The fallacies of web application performance
- José Valim
- June 26th, 2017
- elixir , performance , phoenix
Web application performance has always been a hot topic, especially in regards to the role frameworks play in it. It is common to run into fallacies when those discussions arise and the goal of this article is to highlight some of those.
While I am obviously biased towards Elixir and the role it plays in the performance of web applications, I will do my best to explore fallacies that overplay and underplay the role of performance in web applications. I will also focus exclusively on the server-side of things (which, in many cases, is a fallacy in itself).
Fallacy 1: Performance is only a production concern
In my opinion, the most worrisome aspect of performance discussions is that they tend to focus exclusively on production numbers. However, performance drastically affects development and can have a large impact on developers. The most obvious examples I give in my presentations are compilation times and/or application boot times: an application that takes 2 seconds to boot compared to one that takes 10 seconds has very different effects on the developer experience.
Even response times have direct impact on developers. Imagine web application A takes 10ms on average per request. Web application B takes 50ms. If you have 100 tests that exercise your application, which is not a large number by any measure, the test suite in one application will take 1s, the other will take 5s. Add more tests and you can easily see how this difference grows. A slow feedback cycle during development hurts your team’s productivity and affects their morale. With Elixir and Phoenix, it is common to get sub-millisecond response times and the benefits are noticeable.
When discussing performance, it is also worth talking about concurrency. Everything you do in your computer should be using all cores. Booting your application, compiling code, fetching dependencies, running tests, etc. Even your wrist watch has 2 cores. Concurrency is no longer the special case.
However, you don’t even need multiple cores to start reaping the benefits of concurrency. Imagine that in the test suite above, 30% of the test time is spent on the database. While one test is waiting on the database, another test should be running. There is no reason to block your test suite while a single test waits on the database.
If multiple cores are available, you should demand even more gains in terms of performance throughout your development and test experiences. The Elixir compiler and built-in tools will use multiple cores whenever possible. The next time a library, tool or framework is taking too long to do something, ask how many cores it is using and what you can do about it.
Fallacy 2: Threads are enough for multi-core concurrency
Once we start to venture into concurrency, a common fallacy is that “if a programming language has threads, it will be equally good at concurrency as any other language”. To understand why this is not true, let’s look at Amdahl’s law.
To quote Wikipedia, Amdahl’s law is a formula which gives the theoretical speedup in latency of the execution of a task at fixed workload that can be expected of a system whose resources are improved:
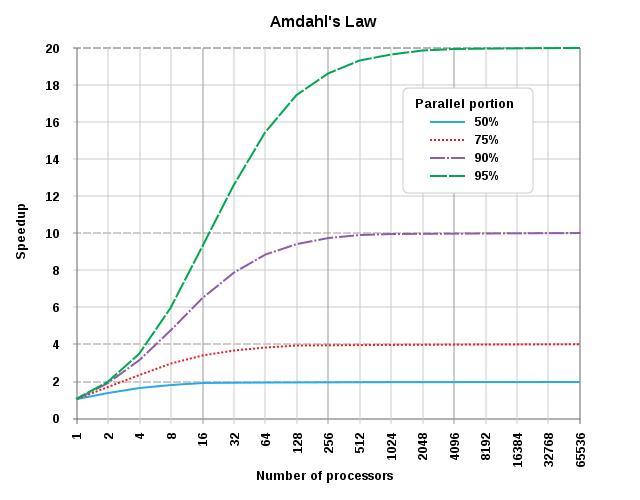 Amdahl's law applied to number of processors. [From Wikipedia, CC BY-SA 3.0.](https://en.wikipedia.org/wiki/Amdahl%27s_law#/media/File:AmdahlsLaw.svg)
Amdahl's law applied to number of processors. [From Wikipedia, CC BY-SA 3.0.](https://en.wikipedia.org/wiki/Amdahl%27s_law#/media/File:AmdahlsLaw.svg)
The graph above shows that the speedup of a program is limited by its serial part. If only 50% of the software is parallelizable, the theoretical maximum speedup is 2 times, regardless of how many cores you have in your system.
If 50% of your software is parallelizable, going from 4 to 8 cores gives you only a 11% speed up. If 75% of the software is parallelizable, going from 4 to 8 cores gives you a 27% increase.
In other words, threads are not enough for most web application developers if they are an afterthought. Instead, concurrency must be part of the default building block. We need good programming models, efficient data structures, and tools. If only a limited part of the software is parallelizable, you will be quickly constrained by Amdahl’s law. Threads are necessary but not sufficient.
Fallacy 3: Conclusions drawn from average response times
Another common fallacy in such discussions is when conclusions are drawn based on average data: “Company X handles Y req/second with an average of Zms, therefore you should be fine”.
Here is why conclusions on this data is not enough. First of all, most page loads will experience the 99% server response (also see Everything you know about latency is wrong for more discussion). Whenever you measure averages, also measure the 90%, 95% and 99% percentiles.
Furthermore, in our experience, clients rarely have performance issues during average load, but rather when there are spikes in traffic. It is easy to plan for your average load. The challenge is in measuring how your system behaves when there is a surge in access. When discussing and comparing response times, also ask for the high percentiles, delays and error rates in case of overloads.
Finally, the server response time as a metric is inherently limited. For instance, a fast server means nothing if the client-side takes seconds to load. Instead of measuring a single request, consider also measuring how the user interacts with the website within certain goals. Let’s see an example.
Imagine that your application requires the user to confirm their account in order to access part of its functionality (or all of it). Now, preparing for a spike in traffic, you cached your home page as well as your sign-up form. Requests start to pour in and you can see your website is responding fairly well, with low averages and even low 95% percentiles. You consider it a success.
The next day, you are measuring how users interacted with your application and you could notice a unusually high bounce rate when the servers were on high load. Further analysis reveal that, even though the response times were excellent, the messaging system was clogged and instead of waiting 30 seconds to receive a message with instructions to confirm their account, users had to wait 10 minutes. It is safe to say many of those users left and never came back.
For queues/jobs, you want to at least measure arrival rates, departure rates, and sojourn time. For this particular sign-up feature, you should measure the user engagement: from signing up, to scheduling the message, to delivering the message, and the final user interaction with it.
Fallacy 4: Cost-free solutions
This is probably the most common fallacy of all.
If you complain a certain library or framework takes a long time to boot, someone may quickly point out that there is a tool that solves the booting problem by having a runtime always running on the background.
If your web application takes long to render certain views, you will be told to cache it.
The trouble is that those solutions are not cost-free and their cost are often left unsaid. It is often joked that “cache invalidation and naming things are the two hard things in computer science”. When there is a bug in cache invalidation, your team will spend time fixing bugs instead of developing new features. Between having a solution that addresses a certain problem and not having the problem at all, I prefer the second.
This fallacy also happens when arguing in favor of technologies that are seen as performance centric. For example, if you want to use Elixir or Go, you will have to learn the underlying abstractions for concurrency, namely processes and goroutines, which is a time investment. If you want your tests to run concurrently when talking to the database in your Phoenix applications, you need to learn the pros, cons and pitfalls of doing so, a topic we covered in depth in Ecto.SQL documentation.
It is important to make those costs explicit and part of the discussions.
Fallacy 5: the web is stateless
Because HTTP 1.1 is said to be (mostly) a stateless protocol, many developers will conclude that their web application must be stateless too. However, this is a fallacy because most applications are not stateless, given the fact that they rely on databases, caching and storage layers to function properly.
If your application or framework stack only allows you to write stateless code, you will always find yourself in need to bring external dependencies for every bit of state you need. Besides the database, you end-up with a separate tool for caching, another for pubsub messages, and so forth. Each additional tool is another layer that you must integrate in your development, testing, and deployment workflows (precisely as we discussed in Fallacy #4). Each of those may affect the user experience too, as they include additional network round-trips.
On the other hand, if you are using a stack that supports stateful applications, such as Elixir, you will find yourself in less need of third-party dependencies. Our article, You may not need Redis, is a good example of how those trade-offs apply in relation to Redis.
Such approaches have become more relevant over the last years due to the use of WebSockets - which are stateful - for building real-time and interactive applications. We have discussed in the past how a stateful stack leads to benefits from development to deployment when WebSockets are involved.
Finally, it is important to note that a stateful stack does not mean you can get rid of all third-party dependencies. Rather, it gives you more options and flexibility when tackling certain problems. You can also learn how Moz went from stateless to stateful to build an application that is simpler, more performant, and ultimately delivers a better user experience and more features.
Fallacy 6: Performance is all that matters
For the majority of companies and teams, that’s simply not the case. Therefore, if you are planning to move to another technology exclusively because of performance, you should have numbers that back up your decision.
Similarly, we often see new languages being dismissed exclusively as “performance fallbacks”, while in many of those languages performance is typically a side-effect. For example, Elixir builds on the Erlang VM and focuses on developer productivity and code maintenance. If you are looking for reducing costs, choosing a language that focuses on productivity and maintainibility will likely be more cost efficient than picking the fastest one. And if you can get extra performance, that’s a nice bonus.
At the end of the day, the discussion about performance is quite nuanced. It is important to know what to measure and how to interpret the data collected. We have learned that performance matter way beyond your production environment and have a large impact in development and testing. And there are no cost-free solutions, be it adding and maintaining a caching layer or picking up a new programming language.
P.S.: This post was originally published on Plataformatec’s blog and updated in Oct/2022 with more references.