Building a custom Broadway producer for the Twitter stream API
- Philip Sampaio
- February 9th, 2021
- broadway, data pipelines
In order to better understand Broadway and GenStage I wrote a custom producer that reads tweets from the Twitter stream API and produces event messages. The experience was pretty fun and this article describes in more details how it went.
What is Broadway?
Think of Broadway as a facilitator to build data processing pipelines.
It is a tool that will connect to your queue system or to a stream of events and will emit those events to consumers according to the demand from those consumers. This feature is called “back-pressure”. There is a nice article by José Valim about how Change.org is using Broadway to process millions of messages without compromise the stability of the system.
Broadway will fit better in an environment that needs to process a lot of data, but it is also recommended for simpler cases that aim to scale with time. If you have a stream of data coming from Kafka, RabbitMQ, Amazon SQS or Google Cloud Pub/Sub, then Broadway already has an adapter ready for you. Otherwise you may need to write your own, so let’s see an example!
The Twitter stream
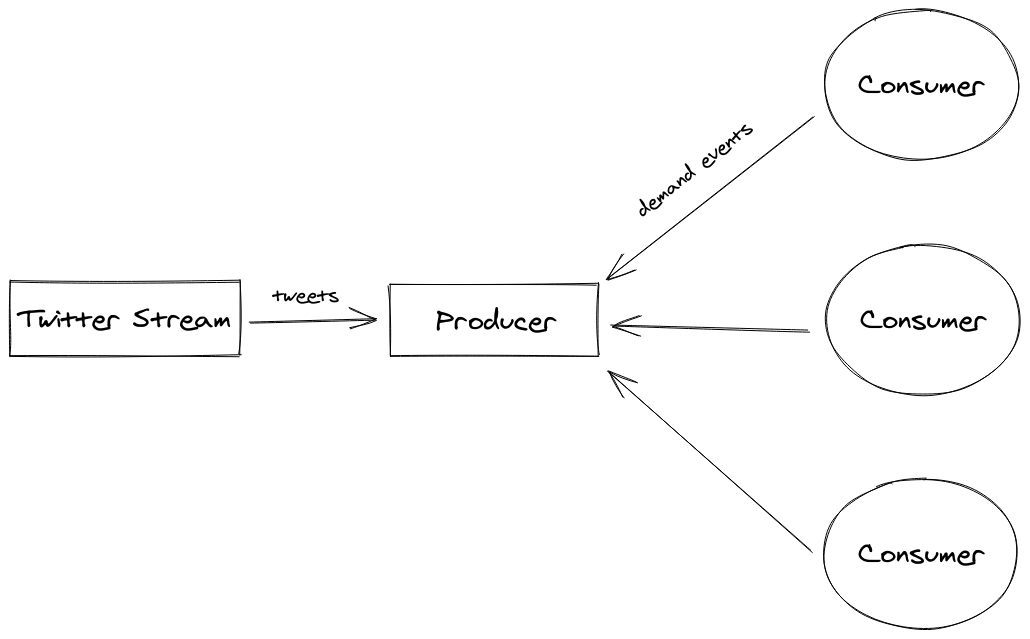
I choose to write a producer based on Twitter stream because it is a HTTP stream, which is simple and can emit a lot of events per second.
I first tried to write a cURL command to fetch data from that stream.
curl --location --request GET 'https://api.twitter.com/2/tweets/sample/stream' -H
'Authorization: Bearer your-token-here'You can setup a new application and grab your token following the Twitter V2 API page.
On the Elixir side we can use Mint to retrieve the data and
have more control of our stream.
Mint is different from most Erlang and Elixir HTTP clients because it does not have a built-in
connection pool and has a process-less architecture. This is a perfect fit for Broadway because
its producers form a pool of their own. Instead of maintaining a pool of producers and a separate
pool of HTTP connections we just have the former and so we avoid overhead of any unnecessary
processes and message passing to achieve maximum performance.
Here is an example of how we can consume the tweet stream:
defmodule TwitterStream do
alias Mint.HTTP2
@twitter_stream_url_v2 "https://api.twitter.com/2/tweets/sample/stream"
def start(token) do
uri = URI.parse(@twitter_stream_url_v2)
{:ok, conn} = HTTP2.connect(:https, uri.host, uri.port)
{:ok, conn, request_ref} =
HTTP2.request(
conn,
"GET",
uri.path,
[{"Authorization", "Bearer #{token}"}],
nil
)
listen(conn, request_ref, token)
end
defp listen(conn, ref, token) do
# Mint sends the last message to `self()`, so we receive here.
last_message =
receive do
msg -> msg
end
case HTTP2.stream(conn, last_message) do
{:ok, conn, responses} ->
# We process "responses" and loop again.
listen(conn, ref, token)
{:error, conn, %Mint.HTTPError{}, _} ->
IO.puts("starting again")
start(token)
end
end
end
We can execute this code by running TwitterStream.start(token) in our IEx terminal. This stream
is always pushing and will never end unless you kill this process.
There is another type of producers which requires the polling of events, and they usually do that from time to time. An example of this is Amazon SQS Broadway. For this article we are going to use a push stream of events from Twitter to our application.
The producer
This is the piece that will gather data from our Twitter stream and deliver tweets as event messages to consumers.
Broadway has an important concept: producers only deliver events when consumers ask for them (the so called back-pressure). We are going to slightly ignore this because our producer is going to deliver events imediately as they arrive, and Broadway will take care of matching the number of events with the demand. But be aware that, whenever possible, it is better to have a more fine-grained control of the demand and stop producing events when no one is demanding them.
Note: Our example does not make usage of back-pressure, because Twitter itself will always emit events, and we can’t tell Twitter to stop it. We will emit the events right away and rely on Broadway’s internal buffer to discard events that are above the capacity of our consumers.
Our producer has to define two main functions: init/1 and handle_demand/2. Those callbacks
are described in the GenStage documentation
because our producer is primarely a GenStage producer. Broadway provides two other
callbacks that can be used to initialize
or stop things in the life-cycle of a Broadway topology.
Let´s go to our init/1 function:
defmodule OffBroadwayTwitter.Producer do
use GenStage
@behaviour Broadway.Producer
@twitter_stream_url_v2 "https://api.twitter.com/2/tweets/sample/stream"
@impl true
def init(opts) do
uri = URI.parse(@twitter_stream_url_v2)
token = Keyword.fetch!(opts, :twitter_bearer_token)
state =
connect_to_stream(%{
token: token,
uri: uri
})
{:producer, state}
end
# ...
end
The most important line of this function is the return:
{:producer, state}
It says to Broadway that this is a producer and defines the state of this producer as the
second element.
We also start the connection and first request to our stream with the function
connect_to_stream/1 that
can be viewed next:
defmodule OffBroadwayTwitter.Producer do
# ...
defp connect_to_stream(state) do
{:ok, conn} = HTTP2.connect(:https, state.uri.host, state.uri.port)
{:ok, conn, request_ref} =
HTTP2.request(
conn,
"GET",
state.uri.path,
[{"Authorization", "Bearer #{state.token}"}],
nil
)
%{state | request_ref: request_ref, conn: conn, connection_timer: nil}
end
# ...
end
The request_ref is a reference to assert that we are reading data from this particular
request. It is going to be used when we start the loop for reading messages. Speaking of loops,
we are going to enter in one: Mint works by sending messages to “self”, which means that every
interaction will generate a message to the process that called it. This way we can continuously
read the stream inside a loop.
We are going to use the handle_info/2 callback that is slightly different from a typical
GenServer: it will return a tuple with 3 elements representing what to do, what messages to
produce and the new state respectively.
After the connection and first request we are going to perform our stream requests inside that
handle_info/2 callback.
defmodule OffBroadwayTwitter.Producer do
# ...
@impl true
def handle_info({tag, _socket, _data} = message, state) when tag in [:tcp, :ssl] do
conn = state.conn
case HTTP2.stream(conn, message) do
{:ok, conn, resp} ->
process_responses(resp, %{state | conn: conn})
{:error, conn, %error{}, _} when error in [Mint.HTTPError, Mint.TransportError] ->
timer = schedule_connection(@reconnect_in_ms)
{:noreply, [], %{state | conn: conn, connection_timer: timer}}
:unknown ->
{:stop, :stream_stopped_due_unknown_error, state}
end
end
@impl true
def handle_info(:connect_to_stream, state) do
{:noreply, [], connect_to_stream(state)}
end
defp schedule_connection(interval) do
Process.send_after(self(), :connect_to_stream, interval)
end
# ...
end
It’s important that we always update the connection value in our state. This is because the stream
expects that we pass the last conn for the next interaction. Another caveat is the need
to restart the connection after the server closes it or after some kind of error. We do that
here by sending another message to self that will reconnect after a few seconds.
Let’s go to the process_responses/1 definition:
defmodule OffBroadwayTwitter.Producer do
use GenStage
# ...
defp process_responses(responses, state) do
ref = state.request_ref
tweets =
Enum.flat_map(responses, fn response ->
case response do
{:data, ^ref, tweet} ->
decode_tweet(tweet)
{:done, ^ref} ->
[]
{_, _ref, _other} ->
[]
end
end)
{:noreply, tweets, state}
end
defp decode_tweet(tweet) do
case Jason.decode(tweet) do
{:ok, %{"data" => data}} ->
meta = Map.delete(data, "text")
text = Map.fetch!(data, "text")
[
%Message{
data: text,
metadata: meta,
acknowledger: {Broadway.NoopAcknowledger, nil, nil}
}
]
{:error, _} ->
IO.puts("error decoding")
[]
end
end
# ...
end
Since Mint is returning a HTTP2 message
containing many possible frames, we are iterating through them and updating the state to retain
that tweet. We are using a special struct for the message
called Broadway.Message,
and that struct has a attribute called acknowledger. This struct has all attributes
Broadway expects for processing the event properly, and the acknowledger attribute is
important because it says which module is responsible for acknowledging the messages after
finishing the pipeline.
Acknowledging is critical in a queue system to mark a given event message as processed or to clean up that message from the system after processing it. In our example we don’t need this because Twitter stream is a firehouse of events.
So far we dealt with the incoming flow of messages. Now we need to implement the handle_demand/2
function. Here is how it looks like:
defmodule OffBroadwayTwitter.Producer do
use GenStage
# ...
@impl true
def handle_demand(_demand, state) do
{:noreply, [], state}
end
# ...
endFor this example, we are relying on Broadway’s internal buffer which is going to store messages until a new consumer asks for them. But, as I said before, in 99% of the implementations we do need to have a better control of how many events we reply to our consumers and really implement a back-pressure mechanism.
Wiring it all up
Now that we have our producer we can setup a Broadway topology to consume events. The topology is
a module with three main functions: start_link which configures this consumer, handle_message
which processes each message and do most of the work, and handle_batch which manipulates a
group of messages. For instance, if you want to process tweets and store them in the database or
in S3, you could submit them in batches using these callbacks. You can define multiple batchers,
each taking a maximum size and a maximum interval for batching. In this example, we will have
a single batcher.
The shape of this module looks like this:
defmodule OffBroadwayTwitter do
use Broadway
alias Broadway.Message
def start_link(opts) do
Broadway.start_link(
# Here you define your consumer's configuration
)
end
@impl true
def handle_message(_, %Message{data: data} = message, _) do
# Here you can work with your message. In our case, a tweet.
# After this, you can choose to route your message to a named
# batch handler using `put_batcher/2`, or just return the message.
message
end
@impl true
def handle_batch(_batch_name, messages, _, _) do
# Here your messages will be processed in groups after being processed by handle_message.
messages
end
end
The OffBroadwayTwitter module will dictate how this pipeline is going to process the events because
it controls many aspects like concurrency and batch size. After processing a batch of messages it
will ask for more events to the producer.
In my example the only task is to print all the Tweets after “upcasing” it:
defmodule OffBroadwayTwitter do
use Broadway
alias Broadway.Message
def start_link(opts) do
Broadway.start_link(__MODULE__,
name: __MODULE__,
# Here is where our producer is configured.
# It is important that our producer is only one because
# our Twitter token can only open one connection at time.
producer: [
module: {OffBroadwayTwitter.Producer, opts},
concurrency: 1
],
processors: [
default: [concurrency: 50]
],
batchers: [
default: [batch_size: 20, batch_timeout: 2000]
]
)
end
@impl true
def handle_message(_, %Message{data: data} = message, _) do
# You can simulate a job by using `Process.sleep(500)` here.
message
|> Message.update_data(fn data -> String.upcase(data) end)
end
@impl true
def handle_batch(_, messages, _, _) do
list = Enum.map(messages, fn e -> e.data end)
IO.inspect(list, label: "Got batch")
messages
end
endStarting the application
Finally we want to test those things together. To facilitate, I added the topology module to my
supervision tree in the OffBroadwayTwitter.Application module:
defmodule OffBroadwayTwitter.Application do
@moduledoc false
use Application
@impl true
def start(_type, _args) do
children = [
{OffBroadwayTwitter,
twitter_bearer_token: System.fetch_env!("TWITTER_BEARER_TOKEN")}
]
opts = [strategy: :one_for_one, name: OffBroadwayTwitter.Supervisor]
Supervisor.start_link(children, opts)
end
endWe have our consumer that requires a bearer token from the system environment in order to properly work.
To start the app, you can run it with IEx:
TWITTER_BEARER_TOKEN=your-token-here iex -S mixYou should see a lot of tweets in upcase :)
Conclusion
Broadway provides a solid model to solve problems of data ingestion. There are producers for the most important queue systems out there, like Amazon SQS, RabbitMQ, Google Cloud Pub/Sub or Kafka so you don’t need to implement a new one. But if you, like me, don’t find the Broadway producer implementation of your choice, you can rollout your own. I hope you have fun in the process! :D
The application from this article can be found at https://github.com/philss/off_broadway_twitter.