Why Elixir is the best language for AI
- José Valim
- February 5th, 2026
- elixir , coding agents , documentation
A recent study by Tencent showed that Elixir had the highest completion rate across models when compared among 20 different programming languages. When combining the results of all 30+ evaluated models, 97.5% of Elixir problems were solved by at least one model, the highest among all languages:
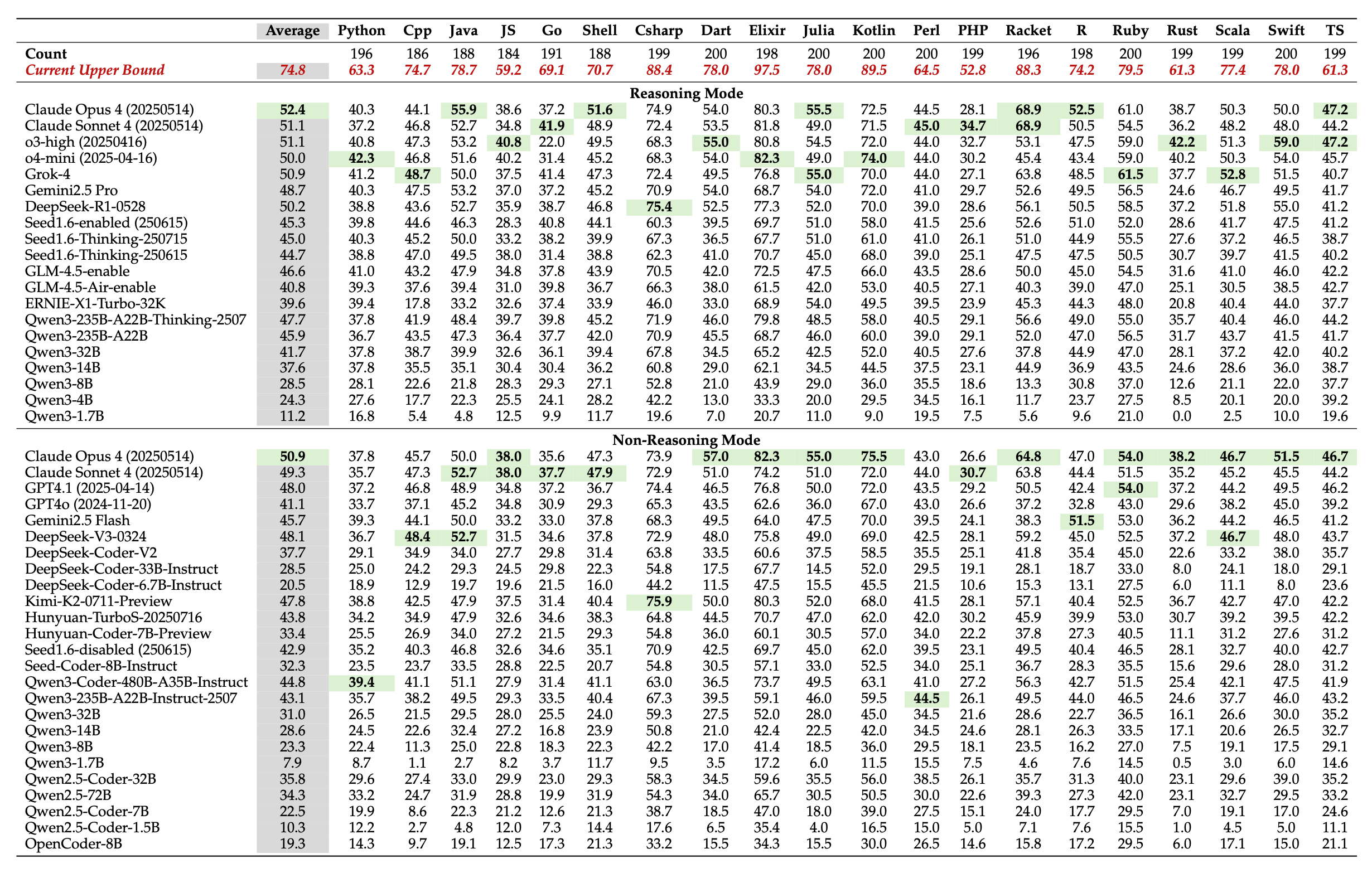
Even when evaluating models individually, Elixir was the top scorer for most models in both reasoning and non-reasoning modes. For example, Claude Opus 4 scored 80.3% on Elixir, followed by C# at 74.9% and Kotlin at 72.5%, with similar results in non-reasoning mode and for Sonnet.
The article has been getting some coverage lately, Theo recently published a video on the topic, so I thought I would add my own take on the possible reasons why Elixir does so well. This article will have two parts, exploring language features and then tooling.
Language and ecosystem: what makes Elixir easy to get right
The first part will cover the language features that positively impact training and LLM generation. This directly relates to the paper, which assessed the problem-solving ability of LLMs across different models, using a single pass.
Immutability and readability
Immutability is possibly my favorite feature in any programming language and it directly impacts how humans and agents understand code. For example, take the following Object Oriented code:
manager = project.getManager()
project.updateVersion()
What can you say about the value of manager after the call to project.updateVersion? Well, you can’t really say anything, because if the project object holds a reference to the manager, the manager can be modified, even demoted from being a manager altogether. In other words, in a mutable language, every method or procedure can impact any object in the system, which makes local reasoning extremely hard, for both humans and agents. This means you often need bring both getManager and updateVersion into the context to understand how the software will behave.
In languages that put immutability first, like Elixir, anything that a function needs must be given as input, anything that a function change must be given as output. This means that, if the code above only changes the project, you would write:
manager = Project.get_manager(project)
project = Project.update_version(project)
If update_version needs to modify both project and manager, you could potentially write it as:
manager = Project.get_manager(project)
{project, manager} = Project.update_version(project, manager)
What goes in and out is always clear, there is no spooky action at a distance. Elixir also makes it obvious where the get_manager and update_version functions are coming from, so no need for guesses there either.
The most known example of how Elixir wrap these concepts together is through the pipe operator, which defines how data is transformed through a series of steps, similar to Unix commands. Here is an example taken directly from the Elixir website:
iex> "Elixir is awesome" |> String.split() |> Enum.frequencies()
%{"Elixir" => 1, "is" => 1, "awesome" => 1}This type of data flow improves local reasoning and postpones the need to bring additional code into the context, avoiding context bloat.
Documentation
One of my focuses with Elixir has always been on the learning experience, which is directly impacted by documentation.
First, Elixir explicitly separates documentation from code comments, as they ultimately serve different audiences and intents. Here is an example:
@doc """
Trim leading and trailing space from the given string.
### Examples
iex> String.trim("foo")
"foo"
"""
@doc since: "1.4.0"
# This would be a code comment
def trim(string) do
...
endFrom the code above, we can say that:
-
There is no conflation between what is the public contract of a function and what is an implementation detail, making it easier to extract the right signal
-
iex>snippets in the documentation can be verified as part of your test suite, which promotes adding “Examples” as part of your documentation, and it also means the training data is likely to be correct -
Bonus: documentation is written as regular Elixir data structures, which means you can generate the correct documentation even when you generate code (meta-programming)
The above lead to an ecosystem that makes documentation a first-class citizen. In fact, you can find the documentation of any Elixir project, including for Elixir itself, in HexDocs. This means you only need to go to a single place to find everything you need to know about Elixir and its ecosystem.
Recently, we took it one step further and indexed all documentation with TypeSense. This means Elixir developers need to run a single command, mix hex.search, and they get a search engine tailored to the exact dependency versions in their project (here is one example from the Livebook package). Of course, we went ahead and exposed it as a MCP server to your coding agents too.
Stability
Stability is often overlooked by many maintainers, who prioritize shipping new features even at the cost of compatibility. On the other hand, the Elixir ecosystem has been extremely stable:
- The Erlang VM and its underlying concepts have been around for decades
- Elixir v1.0 was released in 2014 and, 12 years later, we are still on v1.x
- Similarly, the Phoenix web framework shipped in 2014 and is currently on v1.8
- Even Ecto, our database integration toolkit, currently on v3, had its last major version in 2018
This means everything written about Elixir or Phoenix in the last decade still works. There is no confusion in the training data or in the models about what works and what doesn’t, what is new and what is old. In the same time period, other languages have gone through multiple major versions. Other web frameworks have gone through dozens of major releases with breaking changes.
Of course, this doesn’t mean Elixir or Phoenix haven’t evolved, it rather means the ecosystem allows us the ability to grow without breakage. Whenever we figure out there is a better way to do something, the old approach is deprecated, which will emit a warning pointing to the new version. And if you are using a coding agent, it will pick those warnings and fix them for you.
Tooling: why Elixir is easy to iterate on
The article from Tencent shows that Elixir shines on the first pass, without a coding agent behind it. While this is extremely valuable (getting it right the first time beats needing a second pass!), on the day-to-day we are using harnesses like Claude Code and Codex. This time around, we don’t have the receipts, but we can still intuitively reason about tooling and how it fits agentic workflows.
Fast and accurate feedback
Elixir is a compiled language, which means on every step of the way we are looking for unused variables, undefined functions, redundant clauses, and so forth. Our recent progress on the type system means we can spot bugs for free, with a minimal amount of false positives, while preserving the more expressive nature of dynamic languages.
Elixir also works hard to report most violations as warnings, instead of compilation errors. This means you can continue to iterate and refine the program, instead of being immediately blocked from progressing (and on precommit and CI, you enable --warnings-as-errors to make sure those warnings do not go unnoticed).
But not only that, as a concurrent language, Elixir tooling excels at using all of your machine resources efficiently. Compilation runs in parallel, so do your tests. And when anything goes wrong, error messages and test suite failures are clear and detailed.
Low operational complexity
Thanks to the Erlang VM and its ability to write concurrent and distributed software, we say Elixir offers low operational complexity.
For example, if you are building a web application with Elixir, you most often only need Phoenix and a database. That’s it! Most other stacks push additional complexity on you: you need a cache? Then you need Redis. You need to send messages? It is time for RabbitMQ. You need to process something in the background? Invoke Amazon Lambda. But with Elixir, this is all achieved as part of the language and its runtime.
When a coding agent produces something that doesn’t work, instead of debugging multiple components (a database, the app server, the queue system, etc) and the interactions between them, the surface area it needs to account for is much smaller, making it easier to pin down the problem.
Plus you can run everything locally too with mix phx.server and your development environment closely mirrors the production one. No need to run Docker Compose to orchestrate three additional services. No need to run a mock version of Amazon Lambda or of your cloud provider.
And when it is time to run it in production, there are fewer moving parts too!
Introspection
Finally, the Erlang VM (and therefore Elixir) offers a huge amount of introspection. All your Elixir code runs inside lightweight threads of execution, called processes, and you can introspect each of these processes at any moment: what they are doing, their state, and the work they have pending.
Developers have access to these interfaces through GUI applications and web interfaces, but all of this API is also available programmatically for agents. This is actually one of the reasons why we created the Tidewave MCP, it exposes your running application to coding agents, so they can debug and introspect what is happening during development, like a seasoned engineer would run a REPL in production to diagnose an issue.
Summary
In this article, I laid out my case for why Elixir got the highest completion rate across models among 20 different languages. Most interestingly, these features were designed with the developer experience in mind, yet they build on each other when it comes to LLMs: immutability enables local reasoning, documentation quality ensures good training signal, stability means the training signal stays correct over time.
Beyond single-pass generation, Elixir’s tooling with fast compilation, detailed warnings, low operational complexity, and runtime introspection, also makes it well-suited for the iterative workflow of coding agents, where getting useful feedback quickly matters almost as much as getting it right the first time.